欢迎来到芯果!
欢迎来到芯果!

【通讯转载自网络|本文末尾注明出处】
初创公司又带来创新处理器架构![i]
一家总部位于圣地亚哥的初创公司X-Silicon Inc. (XSi)日前基于开源指令集RISC-V开发了一种新的RISC-V微处理器架构,它将RISC-V CPU内核、矢量功能和GPU加速功能整合到一个芯片中。据 Jon Peddie Research报道,这种 CPU/GPU 混合芯片是开放标准的,据说还将开源,其设计目的是处理包括人工智能在内的各种不同功能,而这些功能通常是由专用 CPU 和 GPU 处理的。
该公司新的 CPU/GPU 混合处理器被设计为 "万能 "处理器。据 JPR 称,业界一直在寻求一种开放标准 GPU,它具有足够的灵活性和可扩展性,能够支持虚拟现实、汽车和物联网设备等各种市场。这种新型 RISC-V CPU/GPU 旨在解决这一问题,为制造商提供可处理任何所需工作负载的单一开放式芯片设计。
X-Silicon 的芯片与其他架构不同,其设计将 CPU 和 GPU 的功能整合到单核架构中。这与英特尔和 AMD 的典型设计不同,前者有独立的 CPU 内核和 GPU 内核。相反,内核本身就是为处理 CPU 和 GPU 任务而设计的。从这个意义上说,它听起来有点像英特尔放弃的 Larabee 项目,该项目曾试图使用 x86 处理图形和其他工作负载。
该芯片采用 X-Silicon 的 C-GPU 架构,将 GPU 加速与 RISC-V 矢量 CPU 内核相结合。该架构有一个 RISC-V 矢量内核,带有 32 位 FPU 和 Scaler ALU。它具有线程调度器、裁剪引擎、光栅化器、纹理单元、神经引擎和像素处理器。该芯片旨在处理人工智能、高性能计算(HPC)、几何计算以及 2D 和 3D 图形等应用。
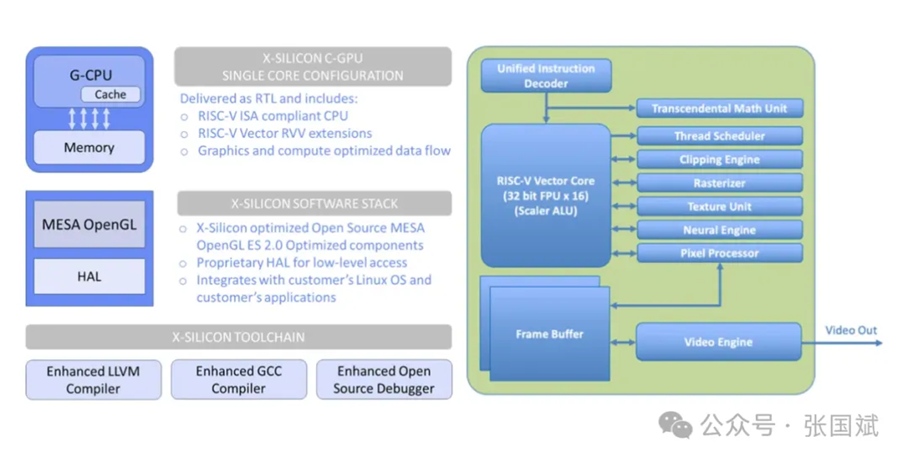
X-Silicon RISC-V C-GPU 详情(图片来源:X-Silicon)
从理论上讲,X-Silicon 的混合芯片能够在同一个内核中处理 CPU 和 GPU 代码,这为它带来了许多优势。该芯片使用开放标准的 RISC-V ISA 处理 CPU 和 GPU,运行单一指令流。由于 CPU 内存空间和 GPU 内存空间之间不需要复制数据,因此执行起来占用内存少,效率更高。
CPU/GPU 内核可以组合成多核设计,使制造商能够根据需要扩展处理能力。在多核格式中,多个内核被平铺在一个芯片上,并使用高速结构进行连接。在这种设计中,还采用了快速片上 SRAM 或 eDRAM 高速缓存,这些高速缓存可作为二级高速缓存,汇集来自多个内核的数据。每个内核都可以根据需要安排独立于其他内核运行图形、人工智能、视频、物理、高性能计算或其他工作负载。
通过这种设计,X-Silicon 的 C-GPU 架构可以运行任何类型的 CPU 或 GPU 工作负载。X-Silicon 声称已经拥有与“融合 GPU 加速”配合使用的 Vulkan 图形 API。这将极大地有助于其在 Android 设备上的开发和采用。
由于新设计基于 RISC-V,任何人都可以使用该架构,而无需支付指令集版税——与 x86 和 ARM 不同。如果它按预期工作,这些芯片可能会震动微处理器行业。理论上,目前使用的标准设计并不像 X-Silicon 声称的那样灵活或强大。
尽管我们可能不需要等很长时间才能知道,但它在实践中是否和纸面上一样有效还有待观察。据报道,软件开发工具包将于今年某个时候向早期合作伙伴发布。
X-Silicon 的低功耗、开放标准、支持 Vulkan 的 C-GPU
X-Silicon Inc (XSi) 是一家总部位于圣地亚哥的初创公司,成立于 2022 年 3 月,X-Silicon 由前硅谷专家组建,旨在通过基于 RISC-V 矢量的统一图形计算引擎(C-GPU)彻底改变 GPU 设计,该引擎能够处理人工智能、高性能计算和 2D/3D 图形任务。其 MIMD 架构可在单核内独立执行 CPU 和 GPU 代码,从而降低内存使用率并提高性能。该公司的多核布局以快速合成器结构为特色,增强了多样化应用的数据聚合能力。在14项专利的支持下,X-Silicon力求通过近内存计算和新颖的硬件设置减少GPU延迟。X-Silicon面向AR/VR、嵌入式设备、汽车等领域,支持标准API和开放式编程,以实现快速开发。最初的知识产权销售面向原始设备制造商和超大规模企业。
为了重塑 GPU 着色器内核,X-Silicon 表示它正在创建一个新的可扩展 RISC-V 矢量型统一计算图形引擎(C-GPU),可以高效计算传统 GPU 从未设计过的下一代工作负载。
这些应用包括人工智能、高性能计算、视觉、几何计算以及 2D 和 3D 图形。该公司表示,其 MIMD 架构具有独特的能力,可以在同一内核中独立运行 CPU 和 GPU 代码,从而实现低内存占用执行、硬件寄存器裸机编程、高性能、低功耗运行等功能,并通过使用单一指令流的开源 RISC-V ISA CPU 和 GPU 取代传统的着色器程序。
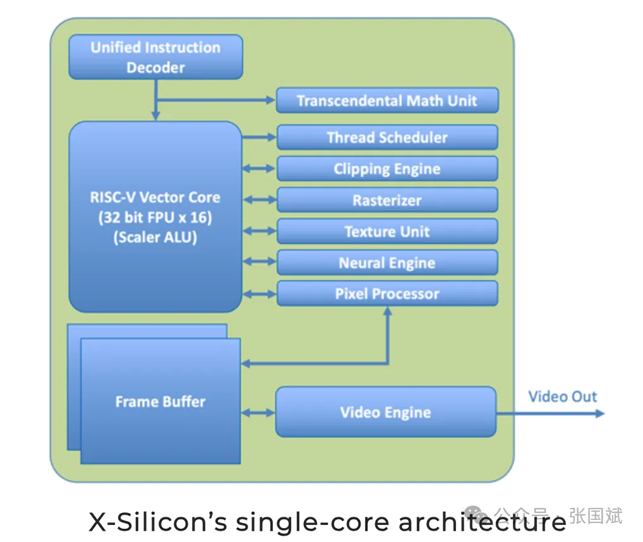
X-Silicon 的单核架构(来源:X-Silicon)
在该公司的多核设计中,多个 C-GPU 内核被平铺在一个芯片上,并使用片上快速合成器结构进行连接,该结构可将每个内核的输出动态聚合到一个公共缓冲区,即用于图形用例的帧缓冲区,或用于编解码器、视频特效处理和人工智能处理的流水线缓冲区,如下图所示。
在这种设计中,快速片上 SRAM 或 eDRAM 高速缓存将作为 2 级高速缓存,可以聚合来自多个内核的数据。计算 RAM(C-RAM)可在内存附近完成常见操作,从而进一步降低带宽并提高性能。该公司称,每个内核都可以通过软件编程来计算图形、人工智能、视频、物理、高性能计算或其他工作负载,而不受所有其他内核的影响。
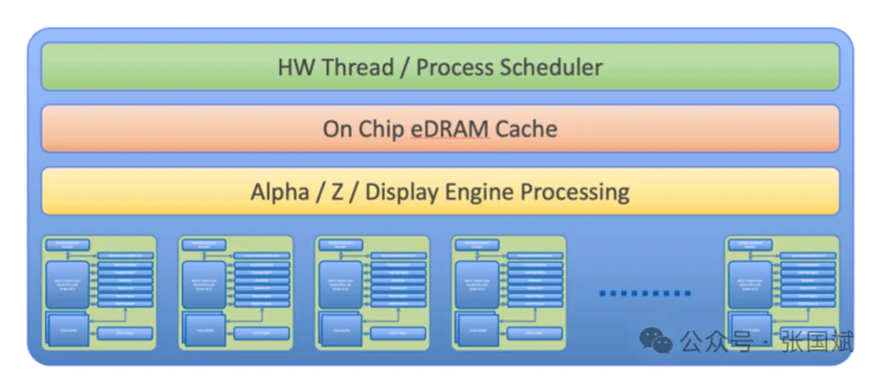
X-Silicon 的着色器架构(来源:X-Silicon)
因此,工作负载可以并行或流水线方式实现,并在一个内核上同时运行,而不是在传统 GPU 上按顺序运行。X-Silicon 表示,它还可以在一个内核上运行操作系统。
该公司声称,它还可以通过近内存计算、统一内存架构和其他新型硬件配置来加速计算,从而减少 GPU 固有的延迟。他们已为此申请了 14 项专利。
动画行业专家、前迪斯尼/Applied Minds/Giant AI 公司的 Eric Powers 评论说:"几十年来,高端动画和特效一直无法改用 GPU 制作最终图像。专业渲染流水线软件的巨大复杂性和规模,加上专用 GPU 设计所带来的跨越内存和平台障碍的巨大成本,根本无法在我们最先进的技术中大规模采用 GPU。像X-Silicon的C-GPU架构这样能让HPC开发人员就地获得直接硬件加速的集成设计,是我们跨越这一界限的唯一未来。
X-Silicon的C-GPU为希望控制其计算和GPU命运的原始设备制造商提供了新的新兴用例的市场机会。它允许新的应用程序接口(包括定制应用程序接口)和为应用定制的生态系统,而不是引导一个应用程序接口去完成它从未想过要完成的任务。它不再要求原始设备制造商和生产商屈从于五大供应商,因为它们的生态系统停滞不前。
X-Silicon的C-GPU为希望控制其计算和GPU命运的原始设备制造商提供了新的新兴用例的市场机会。它允许新的应用程序接口(包括定制应用程序接口)和为应用定制的生态系统,而不是引导应用程序接口去完成它从未想过要完成的任务。它不再要求原始设备制造商和生产商屈从于五大供应商,因为它们的生态系统停滞不前。该公司认为,其市场机会在于新兴市场,如电池寿命更长的娱乐和企业 AR/VR、有显示需求的智能嵌入式设备、需要可预测专用处理的低成本汽车显示器和模块、可穿戴设备、定制动画处理等。
该公司计划支持直接硬件和像素访问,因此对于低内存应用,不需要笨重的驱动程序。该公司表示,X-Silicon 采用开放标准和自己的开放编程模型,这将有助于快速、轻松地开发新的应用案例,并改进现有产品。当然,X-Silicon 还计划支持传统软件生态系统中的各种 API,包括 OpenGL ES、Vulkan、Mesa 和 OpenCL,但该公司还将提供一个硬件抽象层(HAL),允许其他人直接访问以优化开源或创建自己的驱动程序和自定义 API。这一点尤其有趣,因为该架构支持新兴技术,包括传统架构不支持的新渲染模型,如神经辐射场(NeRF)和非三角形基元。

X-Silicon 的单核概念(资料来源:X-Silicon)
该公司计划首先向原始设备制造商、超大规模生产商和其他系统集成商销售IP。首款芯片的上市日期尚未确定。
X-Silicon将CPU和GPU(C-GPU)集成到一个ISA和一个开放的图形操作系统(GOS)平台上,这将对下一代图形渲染的整体软件开发、支持和维护产生深远影响。这将使未来图形技术进入一个激动人心的创新时代,为新兴和传统细分市场提供一种新的图形算法、性能、功耗、灵活性和成本的解决方案。这种方法颠覆了图形世界,将原始设备制造商从传统 GPU 供应商提供的带有复杂 API 和昂贵传统支持的黑盒驱动程序中解放出来。
传统的 GPU SIMD 架构受制于主机 CPU、操作系统和图形服务,限制了创新,并有助于维护现有厂商对市场的控制。新兴的小型垂直市场往往得不到这些传统图形供应商的服务,它们可以开发和支持引人注目的图形解决方案,并在产品生命周期内进行升级和维护。使用新显示技术、新格式和使用范例(VR/AR、360、深度、立体、多平面全息)的下一代产品往往需要新的渲染方法。新的开发和部署模式也需要像本产品这样可从边缘扩展到云的一致架构。X-Silicon 不仅仅是传统 GPU 供应商的开源替代方案,它还准备提供一个全新的技术图形处理框架,该框架融入了最新的人工智能技术,并超越了基于三角形的渲染技术,为创新提供了一个自本世纪初移动设备引入 3D 图形技术以来从未有过的平台。(根据互联网信息以及X-Silicon博文综合报道)
美媒:无需EUV光刻机了[ii]
中国科学家成功在不使用EUV光刻机的情况下实现了芯片制造的重大突破,将芯片速度提升了1000倍。这一突破引起了全球科技界的关注和瞩目,也标志着中国在光子芯片领域的崛起。
在芯片制造领域,EUV光刻技术被认为是一项重要的技术,能够实现更高的精度和更小的纳米级尺寸。EUV光刻机的价格昂贵,限制了其在芯片制造中的应用。中国科学家成功地利用其他技术实现了不使用EUV光刻机的芯片制造,大大降低了芯片制造的成本。
光子芯片作为一种新型的芯片技术,在提升速度和降低功耗方面具有巨大的优势。光子芯片通过使用光子来传输和处理信息,与传统硅基芯片相比,具有更高的传输速度和更低的能耗。此次中国科学家在光子芯片领域的突破,进一步验证了光子芯片作为绕开西方技术控制的途径的潜力。

美国作为传统硅基芯片领域的领导者,也在尽一切努力限制其他竞争对手的发展。美国政府通过技术禁令、贸易限制等手段,试图垄断芯片技术,维护自身在全球科技领域的优势地位。中国科学家的突破表明,中国已经找到了突破的途径,展示了中国在光子芯片领域的实力和潜力。
中国作为光子芯片领域的新兴力量,正积极扩大芯片生产线的产能。中国政府已经投入巨额资金,建设大量的芯片生产线,希望通过增加产能来满足国内市场的需求,并提高在全球市场的竞争力。这也可能带来全球芯片产能过剩和价格竞争加剧的风险。
在中国芯片产能扩大的过程中,也引起了包括美国在内的其他国家的担忧。其他国家担心中国过度依赖芯片产业,可能陷入技术垄断的风险,并对全球市场造成不稳定的影响。中国已经表明了自己在芯片领域的雄心和实力,展示了自主创新的能力。
中国科学家在不使用EUV光刻机的情况下实现了芯片制造的重大突破,将芯片速度提升了1000倍。这一突破展示了光子芯片领域的新兴力量和发展潜力。与此美国在传统硅基芯片领域的优势和对竞争对手的限制,以及中国芯片产能扩大可能带来的全球芯片产能过剩和价格竞争加剧的风险也需要引起重视。中国作为光子芯片制造新时代的机遇和挑战,需要在自主创新和国际合作中找到平衡点。
中国科学家实现了不依赖EUV光刻机的芯片制造突破后,中国在光子芯片领域的发展前景备受期待。光子芯片作为一种新兴技术,具有巨大的潜力和各种应用前景。相比传统的硅基芯片,光子芯片具有高速传输、低能耗和高集成度等优点,被认为是未来芯片发展的方向。
中国政府已经意识到了光子芯片的重要性,投入大量资金和资源来促进其发展。近年来,中国建设了多家国内重点实验室和研发中心,吸引了大量优秀的科研人才投身光子芯片领域的研究。中国也大幅增加了对光子芯片产业的投资,积极建设芯片生产线和生态系统,提高国内产能。
中国的光子芯片产业仍面临一些挑战。技术瓶颈是最主要的问题之一。虽然中国科学家取得了突破性的进展,但与传统芯片制造技术相比,光子芯片技术仍处于起步阶段,存在许多需要解决的问题。全球芯片行业的竞争激烈,尤其是来自美国和其他发达国家的竞争。这些国家拥有雄厚的科技实力和资金支持,也在光子芯片领域进行了大量的研发和投资,势必对中国光子芯片产业构成竞争压力。

为了应对这些挑战,中国政府应当继续加大对光子芯片领域的研发投入,促进创新能力和自主知识产权的提升。加强国际合作,吸收国际先进技术和经验,推动技术的迭代和进步。完善相关政策和法规,保护知识产权,提供支持和优惠政策,吸引更多的投资和人才参与光子芯片产业发展。
总之,中国科学家在不使用EUV光刻机的情况下实现了芯片制造的重大突破,将芯片速度提升了1000倍,标志着中国在光子芯片领域的崛起。这一突破展示了中国光子芯片产业的实力和潜力,中国的光子芯片产业仍面临着技术瓶颈和激烈的国际竞争。中国政府应加大对光子芯片领域的研发投入,积极推动创新能力和自主知识产权的提升,加强国际合作,完善相关政策和法规,以全球视野和开放心态推动光子芯片的发展。
一定年龄的读者将终生被一串特定的嘟嘟声、嗡嗡声、模糊声和机器噪音所困扰。这与我们今天已经习惯的光滑的连接相去甚远,但事实上,我们与万维网的第一次连接是通过拨号连接,如果您使用特定的调制解调器,其速度可达每秒 56.6 kb。
最终,得益于一种相当特殊的芯片——称为 Amati Communications Overture ADSL 芯片组——我们实现了超越。速度过快、图像加载需要很长时间的时代已经一去不复返了,我们迎来了一个新时代,最高速度几乎快了 2,000 倍,达到每秒 100 兆比特。这为充满多媒体的新型互联网铺平了道路。
数字用户线路/环路 (DSL) 是一种通过利用现有电话线通过调制解调器传输数据来访问网络的技术,许多公司正在制定 DSL 的竞争标准。对于标准的出现,我们的一切都归功于 Amati Communications——一家来自斯坦福大学的初创公司。
· 开启网络热潮的芯片
Amati Communications 是众多致力于开发新的互联网访问方法的公司之一,他们设计了称为离散多音 (DMT) 的 DSL 调制方法。根据IEEE Spectrum 的说法,这是一种使电话线类似于数百个子通道的方法,并通过从最差的通道中获取比特并将其捐赠给最富裕的通道来改善传输。它最终成为 DSL 的全球标准,并且芯片组在多年后得到普遍采用。
该公司在整个 90 年代继续推广其标志性芯片组,一开始的销量非常有限,但随着 90 年代接近尾声以及我们接近互联网泡沫,其销量迅速增长。
随后,1997 年,德州仪器 (Texas Instruments) 以 3.95 亿美元收购了该公司,这是该公司在硬件领域的第一笔交易。这家总部位于德克萨斯州的半导体制造商热衷于使用 Amati 首创的 DSL 技术通过电话线提供宽带多媒体服务,包括高速互联网接入和实时视频。
到 2000 年代,该芯片组的出货量已达数百万,更快速的宽带接入也逐渐进入发达国家的家庭和办公室。虽然我们现在可能对它的消亡感到高兴——随着全光纤宽带的兴起——但值得赞赏的是,最初摆脱可怕的拨号音是多么重要,以及它为整个社会带来的可能性。
· 比普通宽带快 450 万倍的光纤
尽快移动大量数据的能力对我们的日常生活变得越来越重要。本月早些时候,研究人员公布了一项实验结果,该结果有助于利用现有光纤基础设施成倍提高传输速度。
英国阿斯顿大学的研究人员成功地以每秒 301,000,000 兆比特的速度通过标准光纤传输数据,这一速度在 Ofcom 于 2023 年发布的宽带性能报告中有所体现。速度和性能的巨大提升归功于之前通过标准传输的未使用的波长光纤系统。
计算机通过光纤传输信息,方法是在称为核心的极薄塑料或玻璃纤维上发送光信号。这些传输通常使用 850、1300 和 1550 纳米的特定光波长来沿线传输信息。为了实现速度的指数级增长,阿斯顿光子技术研究所的 Wladek Forysiak 教授与 Ian Phillips 博士密切合作,利用当今光纤系统中以前未使用的波长带。

光纤通信中最常用的两种波长是传统波段(C 波段)和长波长波段(L 波段)。当C波段不能满足典型的带宽要求时,使用L波段。
Forsiak 和 Phillips 成功地使用了两个额外的光谱带,即扩展波长带(E 波段)和短波长带(S 波段),以增强更常见的 C 和 L 波段的可用容量。研究人员必须开发新的光放大器和光增益均衡器,以有效地利用这些额外的波长带。
利用额外的 E 和 S 波段可产生异常显着的结果。随着技术的发展,供应商有一天可能能够将数据传输能力大大提高,远远超出目前的水平,而无需增加更换整个光纤基础设施的成本。
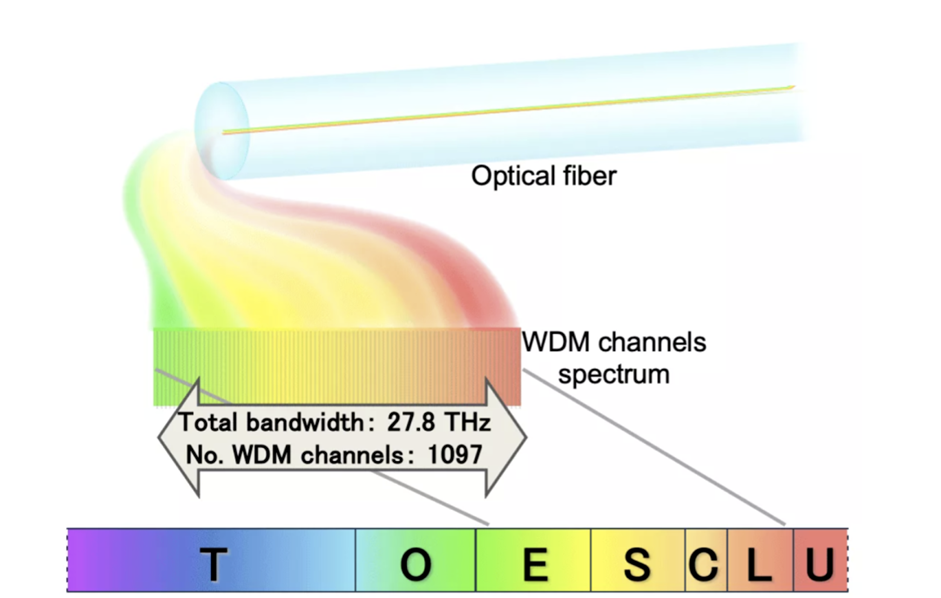
虽然这里达到的速度令人印象深刻,但它并不是有史以来最快的传输速度。两年前,日本国家信息通信技术研究所 (NICT) 的研究人员在达到每秒 1.02 拍比特(即每秒 1,020,000,000 兆比特)的传输速度后创下了数据速率世界纪录。然而,NICT 研究人员采用了四芯定制电缆,而不是标准的单芯线。





